
微服务概念
定义
围绕业务功能构建的,服务关注单一业务,服务间采用轻量级的通信机制,可以全自动独立部署,可以使用不同的编程语言和数据存储技术。微服务架构通过业务拆分实现服务组件化,通过组件组合快速开发系统,业务单一的服务组件又可以独立部署,使得整个系统变得清晰灵活:
- 原子服务:关注单一业务场景
- 独立进程:能够独立部署和交付
- 隔离部署:减小某一物理机crash对全局的影响
- 去中心化服务治理:服务之间的通讯rpc直连,减少集中的负载均衡
缺点
- 基础设施的建设、复杂度高
- 微服务应用是分布式系统,由此会带来固有的复杂性。开发者不得不使用RPC或者消息传递,来实现进程间的通信;此外,必须要写代码来处理消息传递中速度过慢或者服务不可用等局部失效问题
- 分区的数据库架构,同时更新多个业务主体的事务很普遍。这种事务对于单体应用来说很容易,因为只有一个数据库。在微服务架构应用中,需要更新不同服务锁使用的不同数据库,从而对开发者提出了更高的要求和挑战
- 测试一个基于微服务架构的应用是很复杂的任务
- 服务模块间的依赖,应用的升级有可能会涉及多个服务模块的修改
- 对运维的基础设施的挑战比较大
组件服务化
传统实现组件的方式是通过库(library),库是和应用一起运行在进程中,库的局部变化意味着整个应用的重新部署。通过服务来实现组件,意味着将应用拆散为一系列的服务运行在不同的进程中,那么单一服务的局部变化只需重新部署对应的服务进程。我们用 Go 实施一个微服务:
- kit:一个微服务的基础库(框架)
- service:业务代码+ hit 依赖+ 第三方依赖组成的业务微服务
- RPC + message queue: 轻量级通讯
本质上等同于,多个微服务组合(compose)完成了一个完整的用户场景(usecase)。
去中心化
每个服务面临的业务场景不同,可以针对性的选择合适的技术解决方案。但也需要避免过度多样化,结合团队实际情况来选择取舍,要是每个服务都用不同的语言的技术栈来实现,想想维护成本真够高的。
- 数据去中心化:每个服务独享自身的数据存储设施(缓存,数据库等)
- 治理去中心化:避免集中式做流量分发和负载均衡
- 技术去中心化:不绑定某一特定语言
每个服务独享自身的数据存储设施(缓存,数据库等),不像传统应用共享一个缓存和数据库,这样有利于服务的独立性,隔旁相关干扰。
基础设施自动化
无自动化不微服务,自动化包括测试和部署。单一进程的传统应用被拆分为一系列的多进程服务后,意味着开发、调试、测试、监控和部署的复杂度都会相应增大,必须要有合适的自动化基础设施来支持微服务架构模式,否则开发、运维成本将大大增加。
- CICD: Gitlab + Gitlab Hooks + kubernetes
- Testing:测试环境、单元测试、API 自动化测试
- 在线运行时: kubernetes, 以及一系列Prometheus, ELK, Conrtol Panle
可用性 & 兼容性设计
微服务架构采用粗粒度的进程间通信,引入了额外的复杂性和需要处理的新问题,如网络延迟、消息格式、负载均衡和容错,忽略其中任何一点都属于对“分布式计算的误解”。
- 隔离
- 超时控制
- 负载保护
- 限流
- 降级
- 重试
- 负载均衡
一旦采用了微服务架构模式,那么在服务需要变更时我们要特别小心,服务提供者的变更可能引发服务消费者的兼容性破坏,时刻蓮记保持服务契约(接口)的兼容性。发送时要保守,接收时要开放。按照伯斯塔次法则的思想来设计和实现服务时,发送的数据要更保守,意味着最小化的传送必要的信息,接收时更开放意味着要最大限度的容忍冗余数据,保证兼容性。
微服务设计
API Gateway
- 按照垂直功能进行拆分,对外暴露了一批微服务,但是因为缺乏统一的出口面临不少问题:

- 客户端到微服务直接通信,强耦合:不利于服务的更新迭代,要始终保留过往版本的接口
- 需要多次请求,客户端聚合数据,工作量巨大,延迟高
- 协议不利于统一,各个部门间有差异,需要端来兼容
- 面向“端”(不同终端)的API适配,耦合到了内部服务
- 多终端兼容逻辑复杂,每个服务都需要处理
- 统一逻辑无法收敛,比如安全认证、限流
- 新增一个app-interface 用于统一的协议出口,在服务哪进行大量的 dataset join(各种微服务数据的聚合),按照业务的场景来设计粗粒度的 API,给后续业务演进带来很多优势:

- 轻量交互:协议精简、聚合
- 差异服务:数据裁剪以及聚合、针对终端定制化API
- 动态升级:原有系统兼容升级,更新服务而非协议
- 沟通效率提升,协作模式演进为移动业务+网关小组
BFF 可以认为是一种适配服务,将后端的微服务进行适配(主要包括聚合裁剪和格式适配等逻辑),向无线端设备暴露友好和统一的API,方便无线设备接入访问后端服务。
最致命的一个问题是整个 app-interface 属于单点故障,严重代码缺陷或流量洪峰可能引发集群宕机。

- 但各模块也会导致后续业务集成复杂度高,根据康威法则,单块的无线BFF和多团队之间就出现不匹配问题,团队之间沟通协调成本高,交付效率低下
- 很多跨横切面逻辑,比如安全认证,日志监控,限流熔断。随着时间推移,代码变得越来越复杂,技术栈越来越多
- 跨横切面(Cross-Cutting Concerns)的功能, 需要协调更新框架升级发版(路由、认证、限流、安
全),因此全部上沉,引入了 API Gateway,把业务集成度高的 BFF 层和通用功能服务层 API
Gateway 进行了分层处理。

在新的架构中,网关承担了重要的角色,它是解耦拆分和后续升级迁移的利器。在网关的配合下,单块 BFF
实现了解耦拆分,各业务线团队可以独立开发和交付各自的微服务,研发效率大大提开。另外,把跨横切面逻
辑从 BFF 剥离到网关上去以后,BFF 的开发人员可以更加专法业务逻辑交付,实现了架构上的关注分离
(Separation of Concerns).
业务流量实所为:
移动端 -> API Gateway -> BFF -> Mircoservice, 在 FE Web业务中,BFF 可以是nodejs 来做服务端渲染
(SSR, Server-Side Rendering), 注意这里忽略了上游的 CDN、4/7层负载均衡(ELB)。
Mircoservice划分
微服务架构时遇到的第一个问题就是如何划分服务的边界。在实际项目中通常会采用两种不同的方式划分服务便捷,即通过业务职能(Business Capbility)或是DDD的限界上下文(Bounded Context)。
- Business Capbility
由公司内部不同的部门提供的职能。例如客户服务部门提供客户服务职能,财务部门提供财务相关的职能。
- Bounded Context
限界上下文DDD中用来划分不同业务边界的元素,这里业务边界的含义是“解决不同业务问题”的问题域和对应的解决方案域,为了解决某种类型的业务问题,贴近领域知识,也就是业务。
这本质上也促进了组织结构的演进:Service per team

CQRS
将应用程序分为两部分:命令端和查询端。命令端处理程序创建,更新和删除请求,并在数据更改时发出事件。查询端通过针对一个或多个物化视图执行查询来处理查询,这些物化视图通过订阅数据更改时发出的事件流而保持最新。(其实就是读写分离)
在稿件服务演进过程中,围绕着创作稿件、审核稿件、最终发布稿件有大量的逻辑揉在一块,其中稿件本身的状态也有非常多种,但是最终前台用户只关注稿件能否查看,依赖稿件数据库 binlog 以及订阅binlog 的中间 canal, 将稿件结果发布到消息队列katka 中,最终消费数据独立组建一个稿件查阅结果数据库,并对外提供一个独立查询服务,来板分复杂架构和业务。
将稿件审核并写入数据库(archive-result-database)的服务(稿件job)和外部用户查看稿件审核结果的服务(稿件结果)分离开来。
Mircoservice安全
对于外网的请求来说,我们通常在 API Gateway进行统一的认证拦截,一旦认证成功,我们会使用 Header 方式通过 RPC 元数据传递的方式带到 BFF 层,BFF 获取后把身份信息注入到应用的 Context 中,BFF 到其他下层的微服务,建议是直接在 RPC Request 中带入用户身份信息(UserID)请求服务。
API Gateway -> BFF -> Service
Biz Auth -> UID -> Request Args
对于服务内部,一般要区分身份认证和授权。
- Full Trust
- Half Trust
- Zero Trust
gRPC和服务发现
gRPC

多语言:语言中立,支持多种语言。
轻量级、高性能序列化支持 PB(Protocol Buffer)和 JSON,PB 是一种语言无关的高性能系列化框架
可插拔。
IDL:基于文件定义服务,通过 proto3 工具生成指定语言的数据结构、服务端口以及客户端 Stub。
移动端:基于标准的 HTTP/2 设计,支持双向流、消息头压缩、单TCP的多路复用、服务端推送等特性。这些特性是的 gRPC 在移动端设备上更加省电和节省网络流量。
服务而非对象、消息而非引用:促进微服务的系统间粗粒度消息交互设计理念。
负载无关的:不同的服务需要使用不同的消息类型和编码, 例如 protocol buffers, JSON, XML 和 Thrift。
流: Streaming APl。
阻塞式和非阻塞式:支持异步和同步处理在客户端和服务端间交互的消息序列。
元数据交换:常见的横切关注点,如认证或跟踪,依赖数据交换。
标准化状态码:客户端通常以有限的方式响应 API 调用返回的错误。
gRPC - HealthCheck
gRPC 有一个标准的健康检测协议,在 gRPC 的所有语言实现中基本都提供了生成代码和用于设置运行状态的功能。
主动健康检查 health check,,可以在服务提供者服务不稳定时,被消费者所感知,份时从负载均衡中摘除,减少错误请求。当服务提供者重新稳定后,health check 成功,重新加入到消费者的负载均衡,恢复请求。health check 同样也被用于外挂方式的容器健康检测,或者流量检测(K8sliveness & readiness)。
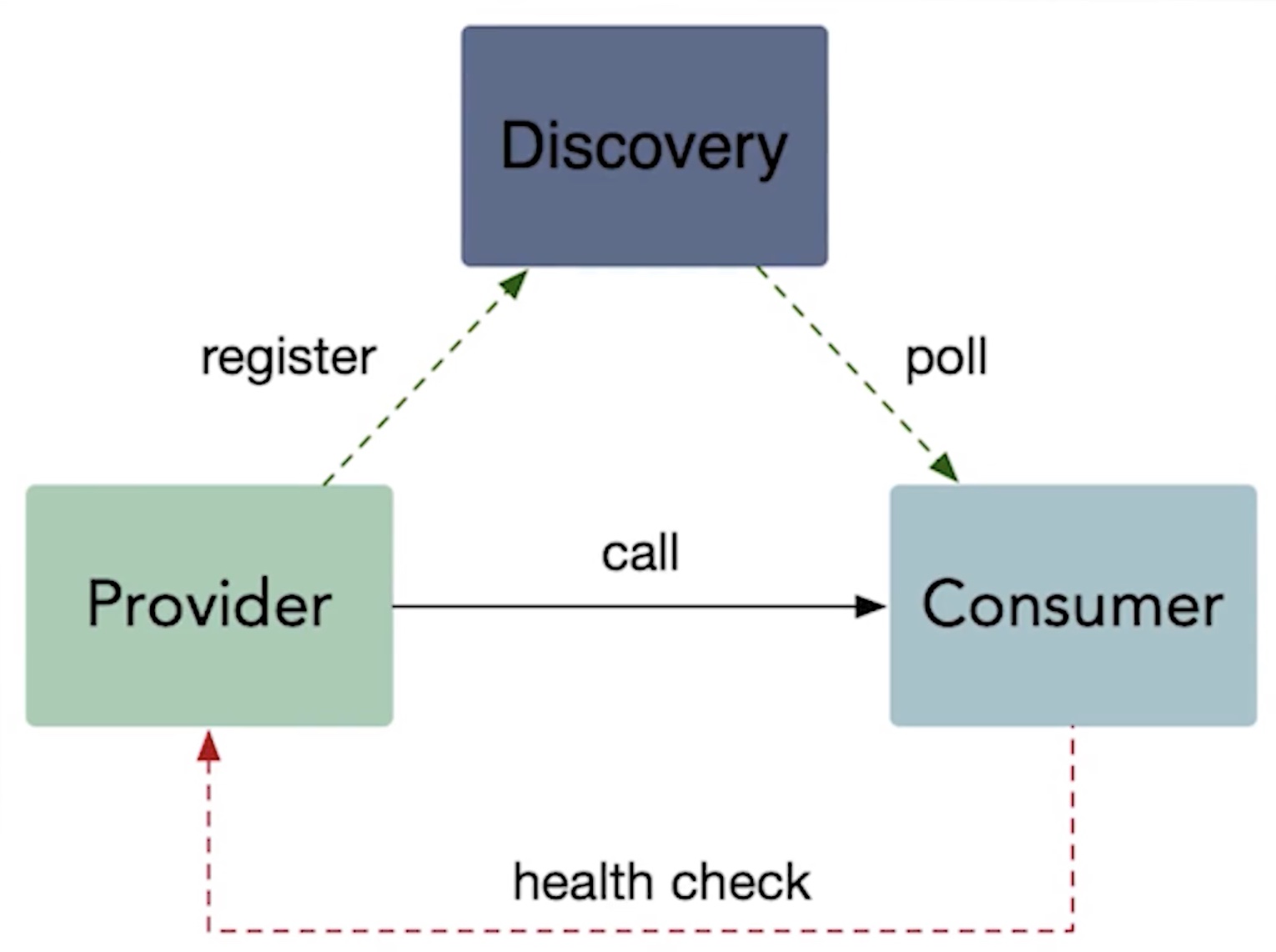
服务发现
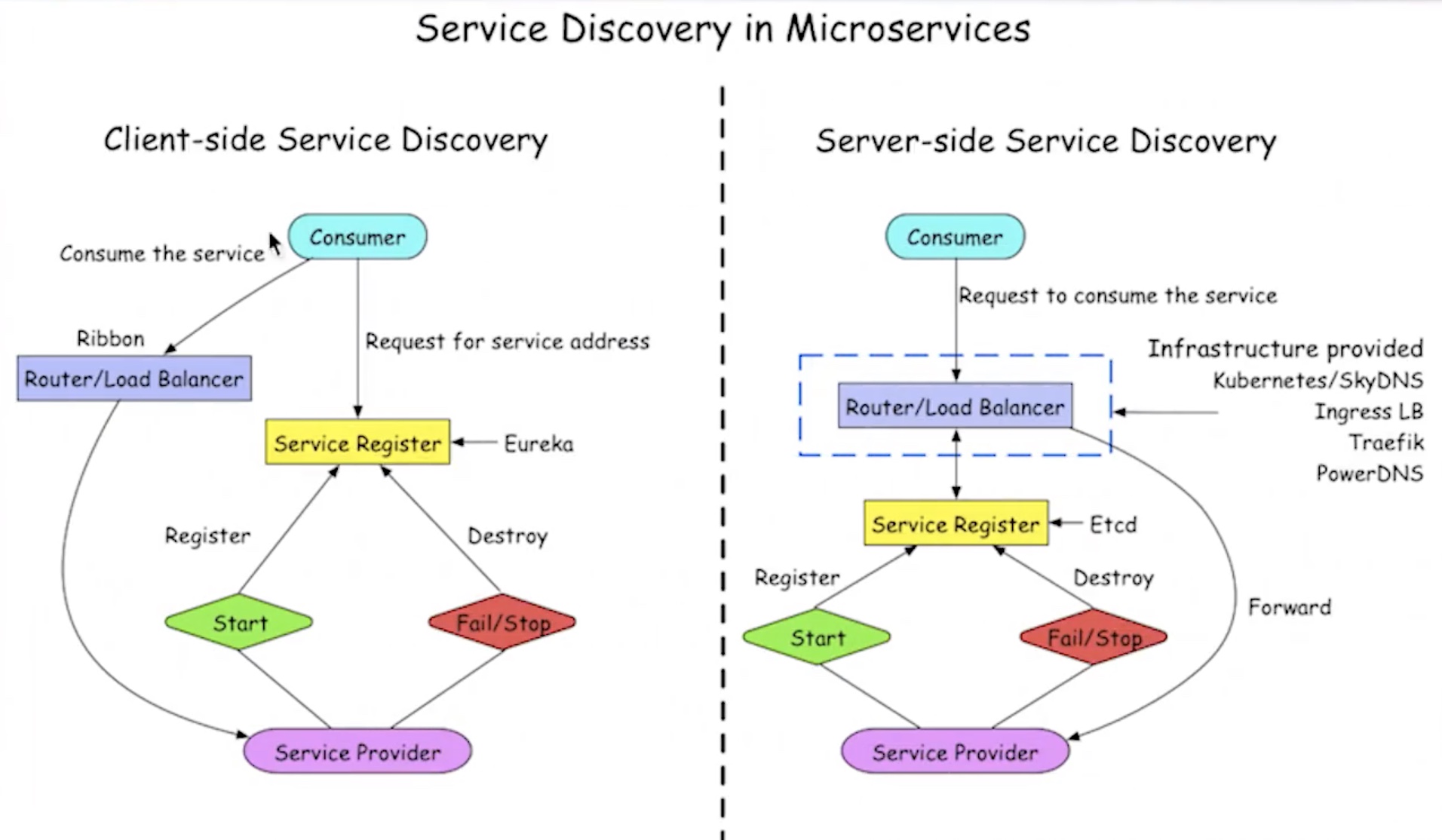
客户端发现
一个服务实例被启动时,它的网络地址会被写到注册表上;当服务实例终止时,再从注册表中删除;这个服务实例的注册表通过心跳机制动态刷新;客户端使用一个负载均衡算法,去选择一个可用的服务实例,来响应这个请求。
服务端发现
客户端通过负载均衡器向一个服务发送请求,这个负载均衡器会查询服务注册表,并将请求路由到可用的服务实例上。服务实例在服务注册表上被注册和注销(Consul Template+Nginx, kubernetesteted)。
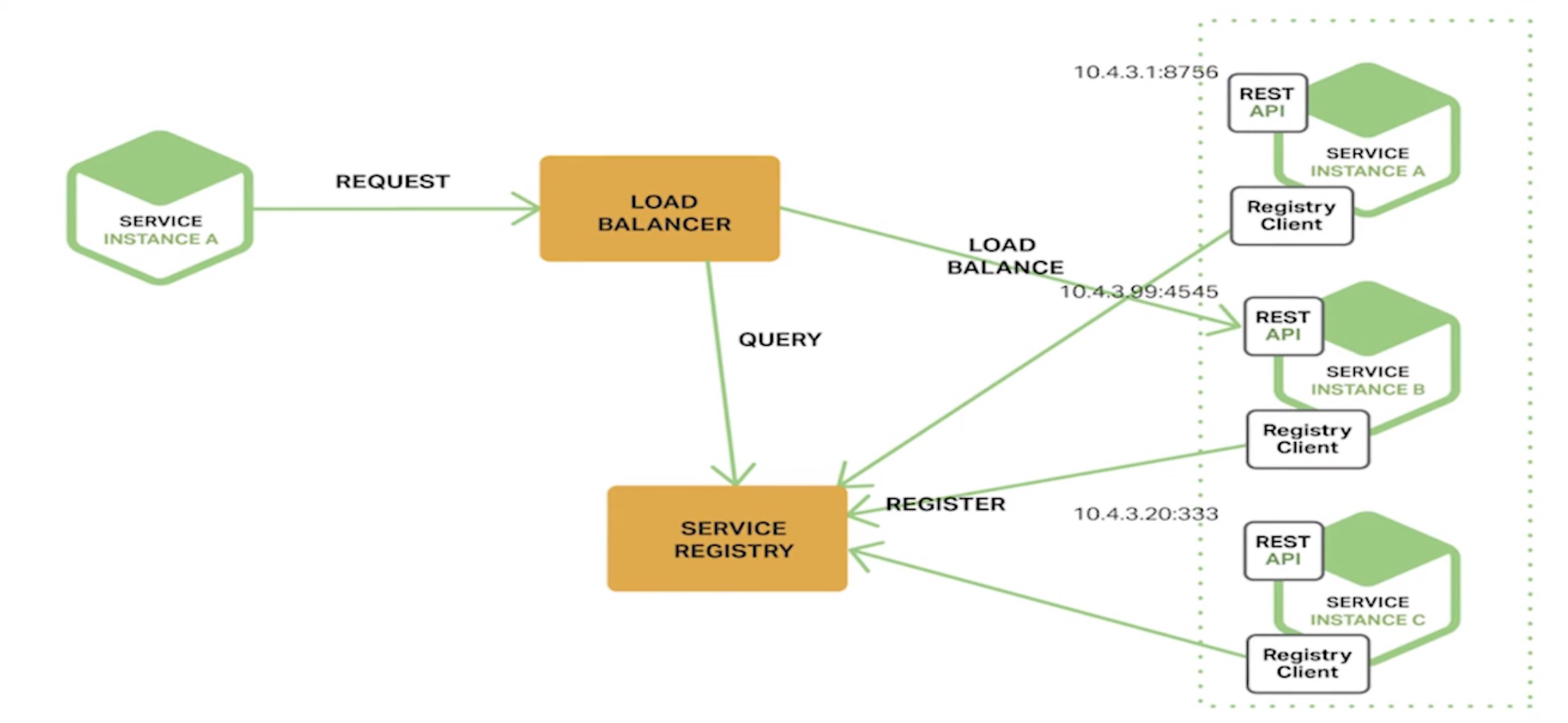
微服务的核心是去中心化,使用客户端发现模式。
- Post title:微服务概览与设计
- Post author:洪笳淏
- Create time:2021-11-28 15:45:00
- Post link:https://jiahaohong1997.github.io/2021/11/28/微服务概览与设计/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.