本系列文章是我在阅读《labuladong的算法小抄》 一书,再结合自己在Leetcode上刷题后的一些体会和总结。本系列文章的所有代码均由Golang语言实现,使用别的语言的读者不妨尝试转换成自己熟悉的语言实现。不过如果你选择用Python来刷算法题,有一个问题需要注意,Python的效率降低,在机试过程中可能出现同一道题,用C/C++或者Golang的人能暴力AC,而用Python却可能会运行超时,会吃不小的亏,还请结合自身情况来考虑选择哪门语言来实现。读者若需要了解更多的细节,还请阅读此书并结合实际多刷刷题。
算法框架 BFS的应用场景 此类问题的本质就是在一幅「图」(树是特殊的图)中找到起始点(start)到终点(target)的最近距离。实际上,此类问题利用DFS也能做到,但是DFS实质上就是回溯算法,时间复杂度很高。BFS的时间代价是O(N),其代价就是空间复杂度很高。在二叉树中,BFS对应的就是二叉树的层序遍历。
这类问题可以有各种各样的变体,比如:1.走迷宫,迷宫中有的格子是围墙,不能通过,要求从起点到终点的最短距离是多少?2.两个单词,要求你通过某些替换,把其中一个变成另一个,每次只能替换一个字符,最少要替换几次?3.连连看游戏,两个方块消除的条件不仅仅是图案相同,还得保证两个方块之间的最短连线不能多于两个拐点。你玩连连看,点击两个坐标,游戏是如何判断它俩的最短连线有几个拐点的?这些问题都没啥奇技淫巧,本质上就是一幅「图」,让你从一个起点,走到终点,问最短路径。这就是 BFS 的本质,框架搞清楚了直接默写就好。
算法思路(Golang) 所有的BFS问题的核心数据结构:队列q用于存储节点。用node指向当前要出队的节点,当该节点出队时,其相邻节点入队。对于非二叉树这种结构(没有子节点到父节点的指针,不会走回头路)的数据形式,还需要一个建立一个map类型来保存已经走过的节点,防止走回头路。
BFS最常见于二叉树中,先给一个二叉树的BFS(层序遍历)框架。
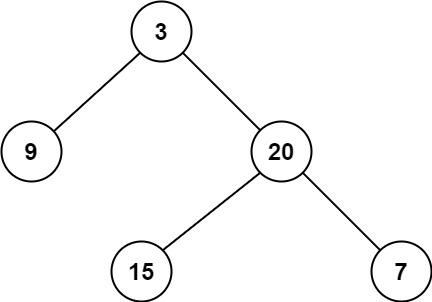
1 2 3 4 5 6 7 8 9 10 11 12 13 示例: 二叉树:[3,9,20,null,null,15,7], 3 / \ 9 20 / \ 15 7 返回其层序遍历结果: [ [3], [9,20], [15,7] ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func BFS (root *TreeNode) [][]int () ret := [][]int {} if root == nil { return ret } q := []*TreeNode{root} for i:=0 ; len (q)>0 ; i++ { ret = append (ret, []int {}) p := []*TreeNode{} for j:=0 ; j<len (q); j++ { node := q[j] ret[i] = append (ret[i], node.Val) if node.Left != nil { p = append (p, node.Left) } if node.Right != nil { p = append (p, node.Right) } } q = p; } return ret }
如果不要求用二维数组分别保存每一层的节点,可以不需要切片p,直接在每个节点出队时将其左右节点送入队列p即可。
通用框架,主要区别在于多了一个map类型用来记录已经遍历过的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func BFS (start NodeType, target NodeType) q := []NodeType{start} m := make (map [NodeType]int , num) m[start] = 1 step := 0 for len (q)>0 { n := len (q) p := []NodeType{} for i:=0 ; i<n; i++ { node := q[i] if node = target { return step } for Node x : node.adj() { if _, ok := m[x]; !ok { p = append (p, x) } } } step++ q = p } }
实际案例(二叉树) 我们来看几道Leetcode上的题目。
给定一个二叉树,返回其节点值的锯齿形层序遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
例如:
3
/ \
9 20
/ \
15 7
返回锯齿形层序遍历如下:
1 2 3 4 5 [ [3], [20,9], [15,7] ]
怎么套到 BFS 的框架里呢?首先明确一下起点 start 和终点 target 是什么,怎么判断到达了终点?
显然起点就是 root 根节点,终点就是最后一个叶子节点。 不过在存储的过程中要注意,奇数行要倒序排列,偶数行正序排列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 func zigzagLevelOrder (root *TreeNode) [][]int q := []*TreeNode{root} ret := [][]int {} if root == nil { return ret } for i:=0 ; len (q)>0 ; i++ { ret = append (ret, []int {}) p := []*TreeNode{} for j:=0 ;j<len (q) ; j++ { if i%2 ==0 { node := q[j] ret[i] = append (ret[i], node.Val) } else { node := q[len (q)-1 -j] ret[i] = append (ret[i], node.Val) } nodeInP := q[j] if nodeInP.Left != nil { p = append (p, nodeInP.Left) } if nodeInP.Right != nil { p = append (p, nodeInP.Right) } } q = p } return ret }
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明: 叶子节点是指没有子节点的节点。
示例 1:
1 2 输入:root = [3,9,20,null,null,15,7] 输出:2
示例 2:
1 2 输入:root = [2,null,3,null,4,null,5,null,6] 输出:5
提示:
树中节点数的范围在 [0, 105] 内
-1000 <= Node.val <= 1000
显然起点就是 root根节点,终点就是最靠近根节点的那个「叶子节点」 ,叶子节点就是两个子节点都是 nil 的节点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 func minDepth (root *TreeNode) int if root == nil { return 0 } q := []*TreeNode{root} step := 1 for len (q)>0 { p := []*TreeNode{} for i:=0 ; i<len (q); i++ { node := q[i] if node.Left == nil && node.Right == nil { return step } if node.Left != nil { p = append (p, node.Left) } if node.Right != nil { p = append (p, node.Right) } } step++ q = p } return step }
给定一个二叉树,编写一个函数来获取这个树的最大宽度。树的宽度是所有层中的最大宽度。这个二叉树与满二叉树(full binary tree)结构相同,但一些节点为空。
每一层的宽度被定义为两个端点(该层最左和最右的非空节点,两端点间的null节点也计入长度)之间的长度。
示例 1:
输入:
1
/ \
3 2
/ \ \
5 3 9
输出: 4
解释: 最大值出现在树的第 3 层,宽度为 4 (5,3,null,9)。
示例 2:
输入:
1
/
3
/ \
5 3
输出: 2
解释: 最大值出现在树的第 3 层,宽度为 2 (5,3)。
示例 3:
输入:
1
/ \
3 2
/
5
输出: 2
解释: 最大值出现在树的第 2 层,宽度为 2 (3,2)。
示例 4:
输入:
1
/ \
3 2
/ \
5 9
/ \
6 7
输出: 8
解释: 最大值出现在树的第 4 层,宽度为 8 (6,null,null,null,null,null,null,7)。
注意: 答案在32位有符号整数的表示范围内。
解题思路:
一开始很自然的想到利用层序遍历,遍历的节点存在以下情况:
当前节点是空节点,则将两个空节点推入下一层的队列;
当前节点不是空节点:
当前节点的左节点为空,则将一个空节点推入下一层的队列;左节点不为空,则将左节点推入下一层的队列;
当前节点的右节点为空,则将一个空节点推入下一层的队列;右节点不为空,则将右节点推入下一层的队列。
当一层遍历完之后,分别从收尾收缩下一层的队列,直到队首和队尾元素均不是空节点为止。然后将此时的队列长度和返回值做比较。
可是,在实际的测试过程中发现内存溢出了。这种方式对内存的占用时巨大的。
然后考虑到完全二叉树的性质,若按层序遍历的顺序给所有的节点编号,则对于每个节点i的左子树,其编号为2*i;其右子树编号为2*i+1,这样就可以为每一个节点编号,直接用每一层的最后一个节点的编号减去第一个节点的编号并加1就是每一层的宽度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 type pair struct { node *TreeNode position int } func max (a,b int ) int if a>=b { return a } return b } func widthOfBinaryTree (root *TreeNode) int if root == nil { return 0 } ret := 0 q := make ([]*pair,0 ) q = append (q, &pair{root,1 }) for i:=0 ; len (q)>0 ; i++ { p := make ([]*pair,0 ) l := len (q) ret = max(ret, q[l-1 ].position-q[0 ].position+1 ) for j:=0 ; j<l; j++ { if q[j].node.Left != nil { p = append (p, &pair{q[j].node.Left,q[j].position*2 }) } if q[j].node.Right != nil { p = append (p, &pair{q[j].node.Right,q[j].position*2 +1 }) } } q = p } return ret }
实际案例(其他数据结构方式) 给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。此外,你可以假设该网格的四条边均被水包围。
示例 1:
1 2 3 4 5 6 7 输入:grid = [ ["1","1","1","1","0"], ["1","1","0","1","0"], ["1","1","0","0","0"], ["0","0","0","0","0"] ] 输出:1
示例 2:
1 2 3 4 5 6 7 输入:grid = [ ["1","1","0","0","0"], ["1","1","0","0","0"], ["0","0","1","0","0"], ["0","0","0","1","1"] ] 输出:3
提示:
1 2 3 4 m == grid.length n == grid[i].length 1 <= m, n <= 300 grid[i][j] 的值为 '0' 或 '1'
算法思路:
遍历整个二维网格,当节点值为1时,以这个节点为起始进行广度优先搜索,当其相邻节点值为1时,进入队列,并将这些入队的节点值置为0。当不再有节点入队,说明已经达到了岛屿的边界,返回原始的循环。同时可以初始化一个map用于记录已经遍历过的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 var m map [int ]int func numIslands (grid [][]byte ) int r := len (grid) c := len (grid[0 ]) count := 0 m = make (map [int ]int , r*c) for i:=0 ; i<r; i++ { for j:=0 ; j<c; j++ { if grid[i][j] == '0' || m[i*c+j] == 1 { continue } else { count++ BFS(grid, i, j) grid[i][j] = '0' } } } return count } func BFS (grid [][]byte , i int , j int ) r := len (grid) c := len (grid[0 ]) q := []int {i*c+j} m[i*c+j] = 1 for len (q)>0 { p := []int {} for k:=0 ; k<len (q); k++ { node := q[k] nodeR := node/c nodeC := node%c if nodeR>0 && grid[nodeR-1 ][nodeC] == '1' { if _, ok := m[(nodeR-1 )*c+nodeC]; !ok { p = append (p, (nodeR-1 )*c+nodeC) grid[nodeR-1 ][nodeC] = '0' m[(nodeR-1 )*c+nodeC] = 1 } } if nodeR<r-1 && grid[nodeR+1 ][nodeC] == '1' { if _, ok := m[(nodeR+1 )*c+nodeC]; !ok { p = append (p, (nodeR+1 )*c+nodeC) grid[nodeR+1 ][nodeC] = '0' m[(nodeR+1 )*c+nodeC] = 1 } } if nodeC>0 && grid[nodeR][nodeC-1 ] == '1' { if _, ok := m[nodeR*c+(nodeC-1 )]; !ok { p = append (p, nodeR*c+(nodeC-1 )) grid[nodeR][nodeC-1 ] = '0' m[nodeR*c+(nodeC-1 )] = 1 } } if nodeC<c-1 && grid[nodeR][nodeC+1 ] == '1' { if _, ok := m[nodeR*c+(nodeC+1 )]; !ok { p = append (p, nodeR*c+(nodeC+1 )) grid[nodeR][nodeC+1 ] = '0' m[nodeR*c+(nodeC+1 )] = 1 } } } q = p } }
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
示例 1
1 2 3 输入:numCourses = 2, prerequisites = [[1,0]] 输出:true 解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
1 2 3 输入:numCourses = 2, prerequisites = [[1,0],[0,1]] 输出:false 解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 2 3 4 5 1 <= numCourses <= 105 0 <= prerequisites.length <= 5000 prerequisites[i].length == 2 0 <= ai, bi < numCourses prerequisites[i] 中的所有课程对 互不相同
算法思路:我们使用一个队列来进行广度优先搜索。初始时,所有入度为 0 的节点都被放入队列中,它们就是可以作为拓扑排序最前面的节点,并且它们之间的相对顺序是无关紧要的。并初始化一个长度为numCourses的切片precourse,用于记录每个节点(课程)的入度。在广度优先搜索的每一步中,我们取出队首的节点 ,将该节点的相邻边(也就是将本课程作为预修课程的其他课程)减1(precource对应索引的值减1)。当节点入度为0时,将其作为下一层节点加入队列中。最后遍历precourse切片,若切片中所有元素为0,说明找到了一种拓扑排序,返回true,否则返回false。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 func canFinish (numCourses int , prerequisites [][]int ) bool precourse := make ([]int , numCourses) for i:=0 ; i<len (prerequisites); i++ { precourse[prerequisites[i][0 ]]++ } q := []int {} for i:=0 ; i<numCourses; i++ { if precourse[i] == 0 { q = append (q, i) } } for len (q)>0 { p := []int {} for i:=0 ; i<len (q); i++ { node := q[i] for j:=0 ; j<len (prerequisites); j++ { if prerequisites[j][1 ] == node { precourse[prerequisites[j][0 ]]-- if precourse[prerequisites[j][0 ]] == 0 { p = append (p, prerequisites[j][0 ]) } } } } q = p } for i:=0 ; i<numCourses; i++ { if precourse[i] != 0 { return false } } return true }
给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, …)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。给你一个整数 n ,返回和为 n 的完全平方数的 最少数量 。完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
1 2 3 输入:n = 12 输出:3 解释:12 = 4 + 4 + 4
示例 2:
1 2 3 输入:n = 13 输出:2 解释:13 = 4 + 9
提示:
算法思路:本题可以采用贪心+BFS的策略,实际上是从上到下逐层构造 N 元树。我们以 BFS(广度优先搜索)的方式遍历它。在 N 元树的每一级,我们都在枚举相同大小的组合。其中每个节点表示数字 n 的余数减去一个完全平方数的组合,我们的任务是在树中找到一个节点,该节点满足两个条件:
(1) 节点的值(即余数)也是一个完全平方数。
下面是这棵树的样子:
首先,我们准备小于给定数字 n 的完全平方数列表(即 powlist)。
然后创建 q队列 遍历,该变量将保存所有剩余项在每个级别的枚举。在主循环中,我们迭代 q 变量。在每次迭代中,我们检查余数是否是一个完全平方数。如果余数不是一个完全平方数,就用其中一个完全平方数减去它,得到一个新余数,然后将新余数添加到 p 中,以进行下一级的迭代。一旦遇到一个完全平方数的余数,我们就会跳出循环,这也意味着我们找到了解。
注意:这里我们使用 set ,以消除同一级别中的剩余项的冗余。
如果看文字难以理解,最好以n=12为例,画一画整个树的层级结构,能有更深的理解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func numSquares (n int ) int powlist := []int {} for i:=1 ; i*i<=n; i++ { powlist = append (powlist, i*i) } set := make ([]bool , 10000 ) level := 0 q := []int {n} for len (q)>0 { level++ p := []int {} for i:=0 ; i<len (q); i++ { node := q[i] for _,value := range powlist { if value == node { return level } else if value > node { break } else { if set[node-value] == false { p = append (p, node-value) set[node-value] = true } } } } q = p } return 0 }
参考资料 1.BFS 算法解题套路框架
2.完全平方数